
栏目分类国裕配资 华人女博士提出高效NAS算法:AutoML一次「训练」适配亿万硬件
你的位置:股票配资网站_配资杠杆平台_正规的股票配资平台 > 正规的股票配资平台 >国裕配资 华人女博士提出高效NAS算法:AutoML一次「训练」适配亿万硬件
发布日期:2024-08-04 13:17 点击次数:157
近日,由加州大学河滨分校主导、乔治梅森和圣母大学共同合作的团队提出,可以利用延迟的单调性来从根本上促进硬件适配NAS —— 即不同设备上的神经架构延迟排名通常是相关的。
当强延迟单调性存在时,可以复用代理硬件上NAS所得到的架构给任意新目标硬件,而不会损失Pareto最优性。通过这种方法,结合现有的SOTA NAS技术,硬件适配NAS的代价可以降到常数O(1)。
目前,论文已经被国际性能建模和分析顶会ACM SIGMETRICS 2022接收。

论文地址:https://arxiv.org/abs/2111.01203
项目地址:https://ren-research.github.io/OneProxy/
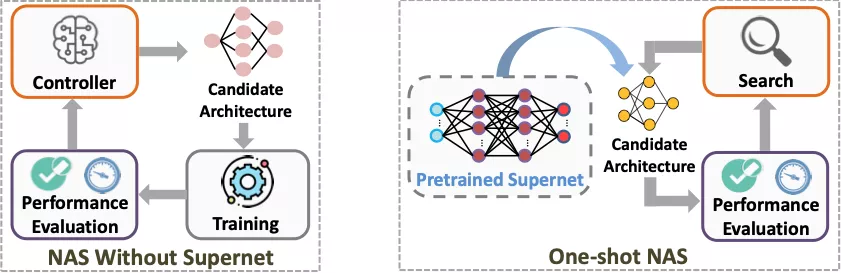
神经架构搜索(NAS)
神经网络是层状结构,每一层可能是卷积层、激活层或全连接层等。
NAS的过程就像搭积木,积木的每一层都有多种选择,比如当前层是卷积层时,使用多大的卷积核就是一种选择。在把各层的选择组合起来之后,便构成了一个完整的神经架构。
通过NAS,一般会得到多个「最优」架构,比如高精度同时高延迟和低精度同时低延迟的架构。而NAS的最终目标就是找出这样一系列在精度VS延迟的权衡中最优的架构(称为Pareto最优架构)。相应地,硬件适配NAS就是对给定目标设备进行NAS,从而找到当前设备上的一系列Pareto最优架构。
由此可见,NAS就是一个「选择-组合」的过程,所以过程中必定会得到非常多个可供选择的架构。从中挑出Pareto最优架构的方法是对这些架构的延迟和精度进行排名而择其优。
对此,本文将使用精度和推理延迟两个指标来衡量一个神经架构的性能。
工作简介
卷积神经网络(CNN)已被部署在越来越多样化的硬件设备和平台上。而神经网络架构极大地影响着最终的模型性能,比如推理精度和延迟。因此,在NAS的过程中综合目标硬件的影响至关重要,即硬件适配的NAS。
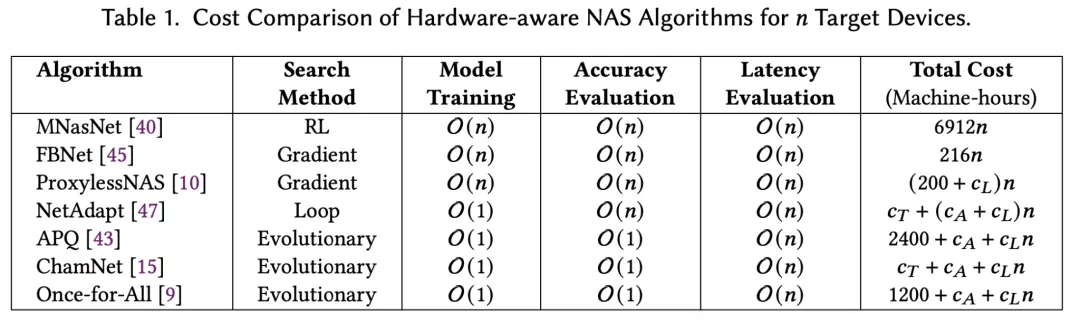
高效进行硬件适配NAS的关键是快速在目标设备上评估各个神经架构的延推理延迟。如果简单地直接测量每个架构的延迟,会导致一次NAS就需要数周甚至数月。所以SOTA硬件适配的NAS主要依赖于为每个设备建立延迟查找表或预测器。
然而构建延迟预测器非常耗时以及需要大量的工程工作。例如,MIT的ProxylessNAS在移动设备上测量了5000个DNN的平均推理延迟,以此为基础构建延迟查找表。
假设每次测量的理想耗时是20秒(根据TensorFlow官方指南),即使不间断地测量,在一个设备上构建延迟预测器也需要27个多小时。类似地,Meta提出的ChamNet收集了35万条延迟记录,仅仅用于在一个设备上构建延迟预测器。
今年ICLR的spotlight工作HW-NAS-Bench也花了一个月在NAS-Bench-201和FBNet模型空间上搜集延迟数据,并为六个设备构建延迟预测器。在Microsoft的最新工作nn-meter中,单是收集一个边缘设备上的延迟测量值就需要4.4天。
这些事实证明了SOTA的硬件适配NAS —— 为每个目标设备构建延迟预测器 —— 成本非常高昂。
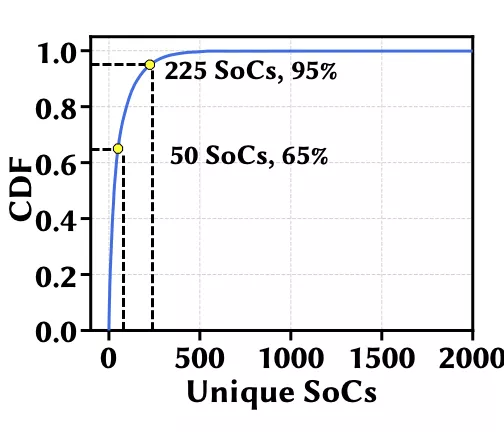
更复杂的是,CNN部署的目标设备极其多样化,包括移动CPU、ASIC、边缘设备、和GPU等。例如,光是移动设备,市面上就有两千多个SoC,排名前30的SoC才勉强各有超过1% 的份额。所以,如何在极其多样化的目标设备上有效地进行硬件适配NAS已成为一项挑战。
在本项工作中,作者解决了如何在不同目标设备上降低硬件适配NAS的延迟评估成本。作者首先证明了神经架构的延迟单调性普遍存在,尤其是同一平台的设备间。延迟单调性意味着不同架构的延迟排名顺序在多个设备上相关。
在此基础上,只需要选择一个设备作为代理并为它构建延迟预测器 —— 而不是像SOTA那样为每个单独的目标设备构建延迟预测器 —— 就足够了。
实验结果表明,与专门针对每个目标设备进行优化的NAS相比,仅使用一个代理设备的方法几乎不会损失Pareto最优性。本项工作被收录于SIGMETRICS’22。
普遍存在的延迟单调性
作为本项工作的根基,作者首先研究了神经架构的延迟单调性,并证明它普遍存在于设备间,尤其是同一平台的设备。本文使用Spearman等级相关系数(SRCC)来定量地衡量延迟的单调程度。SRCC的值介于-1和1之间,两个设备上模型延迟的SRCC越大表明延迟的单调性越好。通常,SRCC的值大于0.9时被视为强单调性。
1. 同一平台的设备间
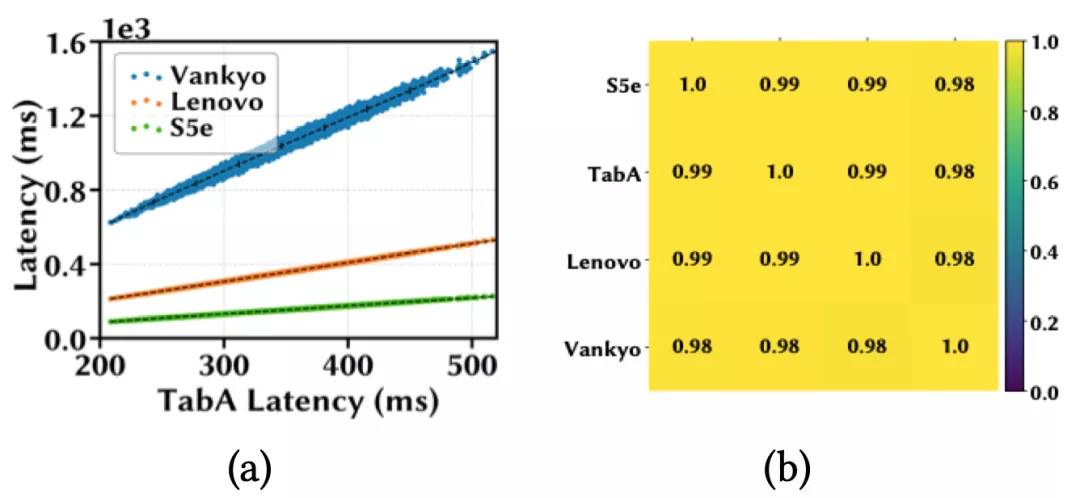
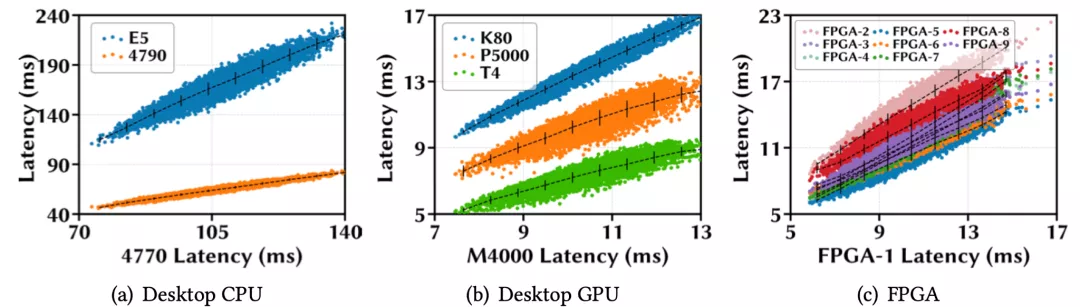
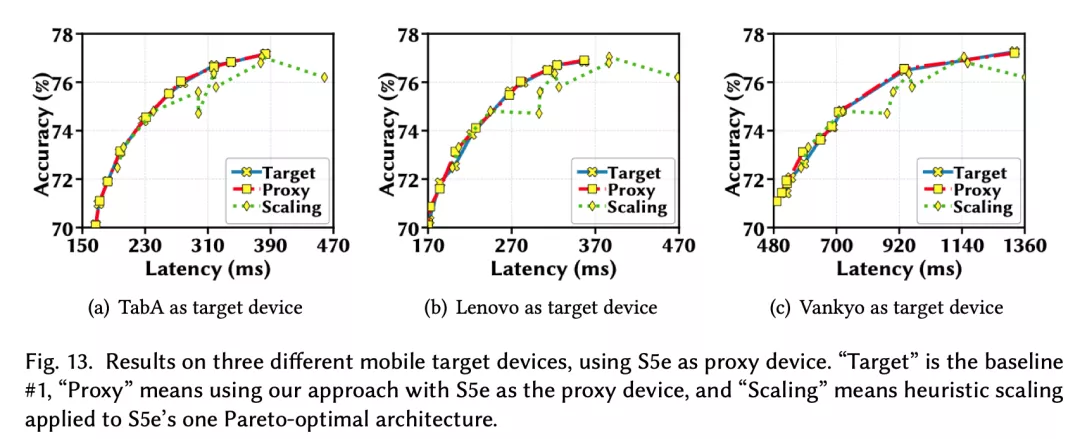
作者首先在四个移动设备上进行了延迟单调性实验,分别是三星Galaxy S5e和TabA,联想Moto Tab和Vankyo MatrixPad Z1;并从 MobileNet-V2搜索空间随机sample了10k个模型。接下来在四个设备上分别部署这些模型并计算它们的平均推理延迟。
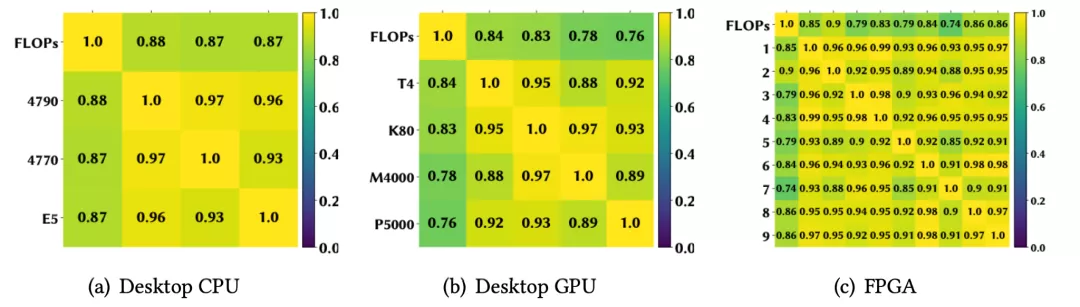
下图(a)用散点表示这些模型在四个设备上的推理延迟;图(b)用热力图来可视化设备之间模型延迟的相关系数,每个方格的颜色深浅和所标数值直观地表示一对设备间的SRCC大小。
作者发现,当一个模型在TabA上运行得更快时,在其他设备上也更快,并且任意一对设备间的SRCC都大于 0.98,这表明这10k个模型在这些设备上有非常强的延迟单调性。
更多的实验还证明,同样的结论对于其他平台的设备间也成立,例如CPU,GPU,和FPGA。
2. 跨平台的设备间
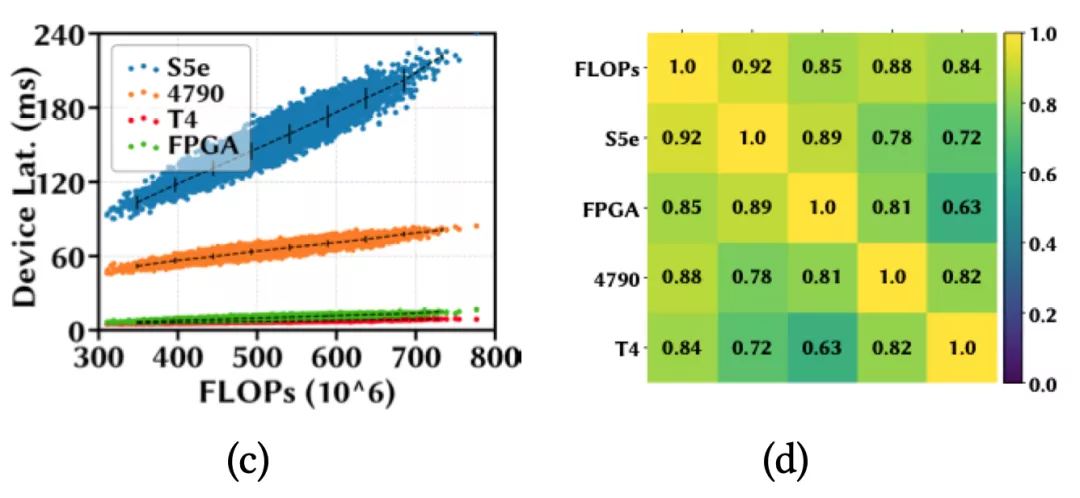
对于跨平台的设备,由于硬件结构通常显著不同,延迟排名的相关性自然而然会低于同平台的设备间。作者在HW-NAS-Bench开源数据集上的实验也证明了此结论(详情见原文附录)。
用一个代理设备进行硬件适配NAS
硬件适配NAS的目的是从数以亿计的可选神经架构中找到适配当前硬件的一系列Pareto最优架构。其中,不同硬件只会影响架构的延迟,而不改变架构精度。
通过前一个章节可以知道不同硬件上架构的延迟排名可能有很强的相关性,既然代理硬件上延迟低精度高的架构可能在其他硬件上也延迟低精度高。那么能不能直接复用一个代理硬件上的Pareto最优架构给所有硬件呢?
作者的回答是:能,但是需要满足一定的条件。
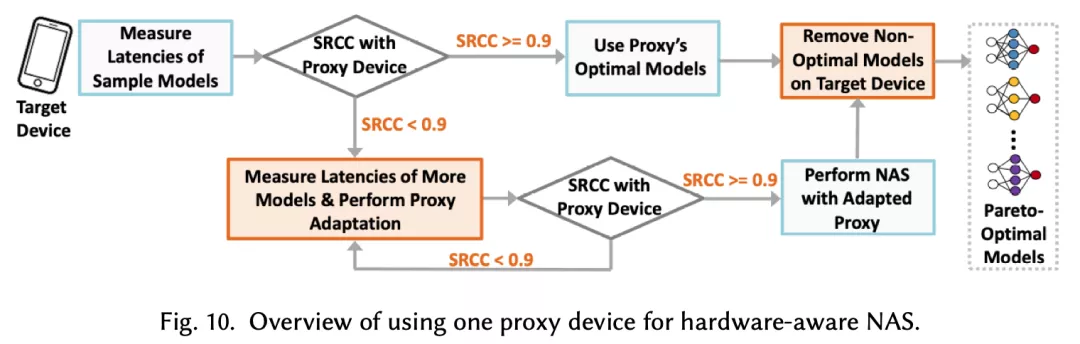
首先,用一个代理设备在目标设备上进行NAS并成功搜索出Pareto最优架构的充分条件是强延迟单调性。当代理设备和目标设备之间的SRCC达不到阈值时,代理设备上NAS搜索出的架构可能与目标的Pareto最优架构有些差距。
实际情况中,设备之间的低延迟单调性可能并不少见,尤其对于跨平台的设备间。针对这种情况,作者提出了一种有效的迁移学习技术来使代理设备的延迟预测器适应到目标设备,从而提高适应后的「新代理」设备和目标设备之间的延时SRCC。
本文通过大量实验证明,可以成功作为代理设备的延迟SRCC阈值在0.9左右。使用迁移学习技术来提高代理设备和目标设备间SRCC的效果如下,具体细节以及算法描述可以参考原文的对应章节。

实验结果
作者在多个主流NAS搜索空间——MobileNet-V2、MobileNet-V3、NAS-Bench-201和FBNet上,对多个硬件设备(包括手机、GPU/CPU、ASIC等)进行了实验,证明了利用延时单调性(结合迁移学习提高单调性的技术),使用一个代理设备来对不同目标设备进行硬件适配NAS的有效性。
总结
快速评估在目标设备上的推理延迟是能够在海量的神经构架空间中实现高效优化的关键步骤。目前普遍采用的为每个目标设备构建延迟预测器的方法无法满足实际中目标设备日益增多所带来的挑战。
在加州大学河滨分校团队所提出的全新方法中,基于延迟单调性,仅仅一个代理设备就足以进行硬件适配的神经构架搜索,并且不失最优性。这省去了大量构建延迟预测器的巨大代价,使得今后针对不同平台和设备快速优化神经构架成为了可能。
作者简介
论文第一作者卢冰倩目前是加州大学河滨分校的博士生研究助理,本科毕业于浙江大学。博士期间一直从事AutoML和NAS的研究工作,包括自动化机器学习模型选择、可扩展的硬件适配神经网络优化,以及硬件适配NAS等。
其导师任绍磊博士,清华大学电子系本科,加州大学洛杉矶分校博士,现任加州大学河滨分校副教授。任教授的研究兴趣包括系统与网络优化(数据中心,云计算,边缘计算等)国裕配资,近年来专注于机器学习及其应用(包括强化学习,AutoML,TinyML等)。